| Copulas: Part II ... a continuation of Part I |
We're talking about generating joint distributions for two variables, say x and y, with prescribed properties.
>Just two?
Pay attention! Before we run, we walk.
For example, we introduced the 1-parameter family of Frank's Copulas:
We also wrote this as:
then C(x,y) is the probability that u ≤ x and v ≤ y. That is: C(x,y) = Prob[u ≤x, v≤y]. | 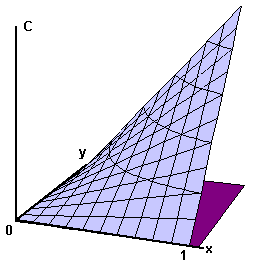 Figure 1 |
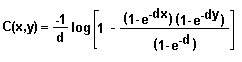
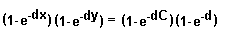
|
To generate Frank's Copula, we introduce (ta-DUM!):
g(z) = - log[ (1 - e-dz) / (1 - e-d) ] Then we generate Frank's Copula via:
That is:
If we solve this for C, we'll get [F1]. >And what does that g-guy look like?
| 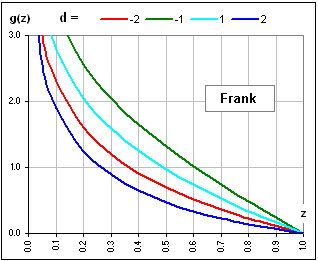 Figure 2a |
|
Of course, that's not the only such g(z) one can invent. How about:
g(z) = -(1/d) (1 - z-d) See Figure 2b? It's also monotone ... but decreasing (for d > -1).
Then, of course, there's Gumbel's Copula where
>I think that's enough. If I pick one, say Gumbo, what do I do with it?
| 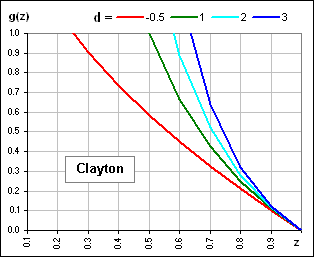 Figure 2b |
| the Right Stuff |
Suppose we have two sets of data, say x and y, and we wish to identify the Mean and Standard Deviation of each and the Correlation
(or maybe we should call it the Dependence) between them.
That's five variables: The Means and SDs, say M[x], M[y], S[x], S[y] and the "Dependence", say K.
>We'll calculate the Dependence using Copulas?
When we're finished we'll be able to generate x- and y-data with the prescribed Means and Standard Deviations and the prescribed correlation
or "dependence".
Although we will usually be speaking of stock returns, the two sets of data may be the average age of drivers in 50 states (that's x1, x2, ... x50) and the annual number of auto accidents in those 50 states (that's y1, y2, ... y50). Or maybe the x- and y-data represent the annual cost of insurance claims and the cost of lawyer's fees. Or maybe the efficacy of a drug or the relationship between $USD and $CAD or maybe ...
>Can we continue?
Okay, but remember that we're interesting in the Dependence of one on the other.
In fact, we could easily look at the distribution of the x- and y-data and invent some distribution function that fits pretty well.
(Normal or lognormal, for example).
Aah, but if we then try to simulate these variables by random selection from our two invented distributions, it is highly unlikely that we'll get any
meaningful correlation.
For example, suppose we do this, assuming that both sets look like they are normally distributed:
- The x-set has Mean = 1.0 and SD = 3.0 and the y-set has Mean = 2.0 and SD = 4.0.
- We generate a hundred values of x- and y-variables by random selection from two normal distributions with these parameters.
- We plot the points (xk, yk) the get a scatter plot and we calculate some correlation.
- Each time we do steps 2 and 3 we'll get different results

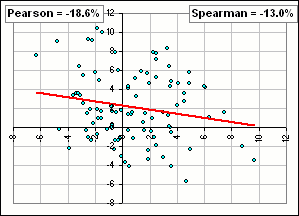
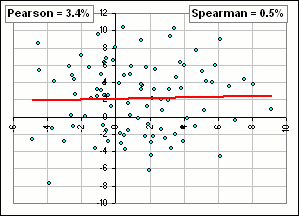
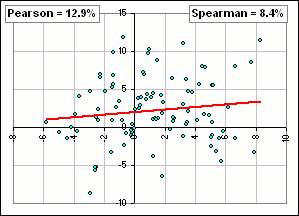
>So use Copulas!
Good idea!
We'll talk about Archimedean Copulas which are generated via [A], above, where C has arguments which both lie in [0,1].
If F1(x) and F2(y) are the cumulative distribution functions for the x- and y-data
(x and y, of course, are NOT restricted to [0,1]),
then F1(x) and F2(y) will lie in [0,1].
For a given x-value, say U, what's the probability that x ≤ U? It's F1(U)
... the cumulative probability distribution for the x variable..
For a given y-value, say V, what's the probability that y ≤ V? It's F2(V)
... the cumulative probability distribution for the y variable.
And what's the probability that x ≤ U and y ≤ V?
It's a joint, cumulative probability F that we'll generate using Copulas, namely:
[B1] F(U,V) = C(F1(U), F2(V)) where F1(U) and F2(V) are the probabilities that x ≤ U and y ≤ V.
This describes a joint distribution function evaluated at U, V where the individual distributions (called the marginal distributions) are
F1 and F2 .
If we select some Copula and we know (or assume) distributions for each variable, then [B1]
will provide a joint distribution.
>Wait! If F1(U) is the probability that x ≤ U and
F2(V) is the probability that y ≤ V then the probability that x ≤ U and y ≤ V is F1(U)F2(V).
Good thinking! Consider this:
We make a random selection of 100 jillion values of x and 60 jillion times we find that x ≤ U.
We conclude that F1(U) = 0.60 from which we conclude that, 60% of the time, x ≤ U.
We also make a random selection of 100 jillion values of y and find that 30 jillion times we got y ≤ V.
We conclude that F2(V) = 0.30 from which we conclude that, 30% of the time, y ≤ V.
We now have 100 jillion selections of both x and y and 60 jillion times we had x ≤ U so, of these, we'd expect 30% will have y ≤ V and 30% of 60 jillion is 18 jillion so the probability of having x ≤ U and y ≤ V is 18-out-of-100 jillion or 0.18 which is F1(U)F2(V) = 0.60*0.30.
>So why all the fuss about copulas and joint distributions and ...?
We'd use F = F1F2 if the two variables were independent.
However, we're talking about "dependence" so, having selected an x, the y value may be restricted because of that dependence.
>Why didn't you say that before?
Hey! I'm just learning 'bout this stuff. A few days ago I didn't know a copula from a cupola.
){kind=link}
>Okay, but in [B1], you're assuming you know the individual distributions, right?
Yes, in this case, but ...
>And you'd get a different joint distribution every time you decide to change copulas, right?
Well, yes but ...
>If I just gave you the joint distribution, would you accept it or would you pick a copula?
Aah, good point! In fact, no matter what joint distribution Function you gave me,
there'll always be a Copula satifying [B1].
>You're kidding, right? No matter what joint distribution I invent?
Yes ... that's Sklar's Theorem. In fact:
- A Copula connects a given joint distribution Function to its marginal distributions ... them's the individual distribution functions F1, F2.
- The Copula describes the dependence between variables, regardless of their individual distributions.
- Copulas were invented (in 1959?) in order to isolate the dependence structure between variables.
- No matter what F1 and F2 are, the numbers F1(U) and F2(V) will be uniformly distributed on [0,1] !
- Since the arguments of C are just uniformly distributed random variabes (namely F1(U) and F2(U)), what's left is their dependence.
- In fact, we can link together any two marginal distributions (F1, F2) and any Copula and we'll get a valid joint distribution Function.
- In fact ...
|
>Okay! Can we continue?
Sure. Let's ... >Wait! Don't you find that confusing? First you say x and y, then u and v, then U and V? Here's a picture ... Figure 3. x is our random variable and U is a particular value of x and if we ask: "What's the probability that x ≤ U?" the answer is u = F1(U). Note that x hence U can have any value, but 0 ≤ u ≤ 1. | 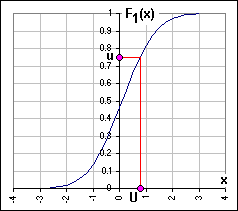 Figure 3 |
| More stuff |
We've noted that u = F1(U) and v = F2(V) are just uniformly distributed variables, regardless of the functions F1 and F2.
Further, u and v are uniformly distributed in [0,1] ... since they're probabilities.
Further, if we solve for U and V we'd get: U = F1-1(u) and V = F2-1(v)
... where F1-1 and F2-1 are
the inverse functions.
>Inverse what?
If a = f(b) = b3 where f is the "cube function", and we solve for
b = f -1(a) = a1/3, we call that "cube root" function the inverse of the cube function
and use the notation f -1. Got it?
We do that whenever we can solve "backwards", giving the name
f -1 to the inverse of f and the name g -1 to the inverse of g and
...uh, that reminds me. If we look back at [A],
it says: g(C) = g(x) + g(y).
If we solve for C we'd write this as
C = g -1 ( g(x) + g(y) ).
>Yeah ... I got it.
I have a better example. Look again at Figure 3.
If we know U we get to u by going North then West, along the
red line to u = F1(U).
However, if we know u, we go East then South to U = F1-1(u).
>I got it!
Anyway, we can now write [B1] as:
[B2] C(u, v) = F(F1-1(u), F2-1(v))
>zzzZZZ
We're almost there! Our new equation involves just the uniformly distributed variables u and v, see?
To model them we just select numbers at random in [0,1] using, for example, Excels RAND() function, see?
>zzzZZZ
Indeed, we can now conclude (via Sklar's theorem) that:
- If we know F1 and F2, the distributions of x and y
(where F1(U) is the probability that x ≤ U
and F2(V) is the probability that y ≤ V),
and we pick our favourite Copula, then the joint distribution F is given by [B1]:
F(U,V) = C(F1(U), F2(V))
- If we know the joint distribution F and marginal distributions F1 and F2, then
there is a unique Copula according to [B2], namely:
C(u, v) = F(F1-1(u), F2-1(v))
>Huh?
The x-variable may be normally distributed and the y-variable may be lognormal or maybe a t-distribution or maybe uniformly or maybe ...
>Yeah, but what Copula and how do you change the dependence?
Having chosen your favourite Copula, you change the parameter, such as the d in Clayton's Copula: g(z) = [ x-d + y-d - 1 ]-1/d
Aah, but what Copula, eh?
>That's what I said!
 for Part III
for Part III