| Normal, Log-normal and other assorted Distributions ... continued from Part II |
We start with a jillion numbers: g1, g2, g3, ... gN where N is very large. For convenience, we'll refer to this set as simply {g}.
>Wait! What are we talking about here? Haven't we done this before?
Yes, but I want to talk about different distributions of, say, monthly stock gains and ...
>Okay, please proceed.
Gee, thanks. Anyway, we count how many of these numbers are less than x.
It'll depend upon x, so we'll call it F(x).
>We'll call it? What's it?
We're counting the number of g's less than, say, "2".
That number ... that's F(2). The number less than 1 we'll call F(1). The number less than ...
|
>Okay, I get it, but a picture is worth a thousand ... Okay, here's a picture Every time we get a count, we get a point on the chart. For example, the number of g's less than 2 is 6616. The number less than 0 is 4011. >It looks like you're working with 10,000 numbers. >And it looks like they all lie between -10 and +10. >So N = 10,000. | 
|
Notice that we can calculate the number of g's
between x=0 and x=2:
There are 6616 less than 2 and 4011 less than 0 so there are
6616-4011=2605 between x=0 and x=2.
Usually, we divide F(x) by the number of members of the set {g} - in our case 10,000 - so F(x) gives the fraction which are less than some given x. The graph of this "new" F(x) would then go from 0 at the far left to 1 on the far right and, for our example, the fraction less than 2 is 0.6616 and less than 0 is 0.4011 so 0.2605 or 26.05% of the g's lie between 0 and 2.
>Are these numbers called g or are they called x? It's confusing, I mean ...
Uh ... I'm calling the original numbers g, like g1, g2, etc..
However, when I want to talk about a particular g-value, I use the symbol x. For example, I
refer to the number of g's less than some particular value x. Clear?
>No. Anyway, you've got some guy called F(x). Does he have a name?
The Cumulative Distribution Function.
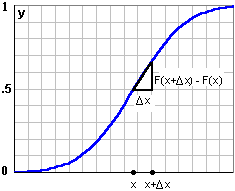 |
In general, if we wanted to know the fraction of g's between x and
x+Δx,
it'd be F(x+Δx) - F(x) and, for small Δx, we can write F(x+Δx) - F(x) = F'(x)Δx where F'(x) is the slope of F(x), at the place x. We'll call this slope f(x), so and the fraction of g's between x and x+Δx is then: and if we sum of all these fractions we'd get all the g's, so: |
The fraction lying in an interval of length Δx, at the place x, is f(x) Δx and Σf(x) Δx = 1
>I take it that Σ
means we add them all up and "1" means we've included 100% of the g's.
Right.
For small Δx, we write this sum as an integral
and get our first magic equation:
(1) 
|
>An integral?
Don't worry about it. It's a wee bit of calculus.
>A very wee bit?
Yes. I promise.
Okay, now we want to know the average value of the g's. We do this like so:
- Suppose we're determining the average grade on a test and we know that a fraction 0.1 of the students (that's 10%) got a grade of 45, 0.3 got a grade of 65 and 0.6 got a grade of 85.
- The average grade is 0.1(45) + 0.3(65) + 0.6(85) = 75
>Don't tell me! To get the average of the g's we'd determine the fraction having the value x1, say n1, the fraction having the value x2, say n2, etc., then ... uh ... we'd calculate n1(x1) + n2(x2) + ...
Very good. You've been eating your smart pills. Okay, for the case we're considering,
where
the fraction having the value x1 is
f(x1)Δx,
the fraction having the value x2 is
f(x2)Δx
etc.,
we'd calculate:
x1f(x1)Δx
+ x2f(x2)Δx + ...
= Σ x f(x) Δx
which gives us our second magic equation:
(2) 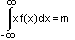
|
Now we want to measure how far the g's are from their Mean, m. We calculate the average of the squared deviations:
(1/N){(g1-m)2 + (g2-m)2 + ... }but, as above, we count the fraction having the value x1, namely f(x1)Δx, and the fraction having the value x2, namely f(x2)Δx, etc. and use:
(x1-m)2f(x1)Δx + (x2-m)2f(x2)Δ + ...which brings us to our third magic equation:
(3) 
|
>And S is called ... what?
S, the Root Mean Square (or RMS) deviation is called the Standard Deviation.
|
>So, what does f(x) look like? >So, what does f(x) look like?
>And f(x), I presume, is the "Density". | 
|
|
(4) Normal Distribution
|
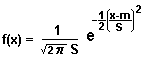
The funny guys (like 2π) are there so that equation (1) is satisfied.
Also, the graphs we've used above are from a Normal Distribution with m = 1 and S = 3.
The next is the Log-normal Distribution. In this case, we assume that the logarithms of the g's have a Normal Distribution. Because we're considering log(g1), log(g1), etc., the numbers g1, g2, etc. had better be positive!
>Why?
Because log(g) isn't defined (as a real number) unless g > 0. Hence, when considering a Log-normal distribution of returns, we consider g1, g2, etc. to be the Gain Factors.
>Remind me.
If the monthly return is 2.3%, the Gain Factor for that month is 1.023, meaning that $1.00 will grow to $1.023 during that month. Since the Gain Factors are always positive - assuming you don't lose everything in one month (!) - then we can consider the distribution of their logarithms.
>I assume that the logarithm is the natural log.
Yes, to the base e = 2.71828, roughly. Anyway, here's the picture.
|
If we plot the distribution of logarithms, log(g1), log(g2), ...
log(gN), we'd get a Normal curve as shown, where m and S are now the Mean and Standard Deviation of the logarithms! >That sounds tough, I mean ... Actually, the Mean is easy. For example, suppose {g} were a set of annual returns. The average logarithm, m, is
| 
|
That allows us to write the Log-normal density distribution like so:
- Put z-m=log(x/G)
- Since we must satisfy equation (1), above, then changing from z to x requires changing
Δz to (1/x)Δx
(that is, dz = dx/x) so we must change f Δz to f Δx/x - We get, finally f(x), our density distribution for x (as opposed to, f(z), the distribution for z):
| with x > 0 since x is now a Gain Factor ... and S is now the Standard Deviation of log(x) ! |

>We must change f Δz to
f Δx/x ? What's that about?
It's because dz = d(log(x) = (1/x) dx ... but don't worry about it.
>You promised just a wee bit of calculus!
Yes ... uh, it's because of the logarithm, you see. If x changes by a tiny amount from x to
x+Δx, then its logarithm will change from log(x) to
log(x+Δx) = log(x[1+Δx/x])
= log(x) + log(1+Δx/x) and, for tiny values of
Δx/x, log(1+Δx/x) =
Δx/x so the logarithm will change by a tiny amount
Δx/x and we can see that x in the denominator so that ...
>Please ... please, continue.
Okay. Notice that, if
- F(x) is a Normal cumulative distribution with Mean = 0 and Standard Deviation = 1, then
- F((x-A)/B) is a Normal distribution with Mean = A and Standard Deviation = B, and
- F([log(x)-A]/B) describes a distribution where it's log(x) which has a Normal distribution and it's log(x) which has the Mean = A and Standard Deviation = B.
>Number 3 is our Log-normal distribution, right?
Right. Notice that, for the Log-normal distribution, the geometric Mean, G, plays the
central role (unlike the Normal distribution where it's the arithmetic Mean).
But if we choose the Mean m and Standard Deviation S to match S&P 500 returns, neither distribution is a very good match.

|
>So?
So, let's try another tack where the horizontal axis corresponds to the Gain Factors, not the gains themselves, so 0.8 means a gain of 0.8 - 1 = - 0.2 or a 20% loss and 1.1 means a 10% gain and ... >Yeah, yeah. I got it.
|
 |
Yes. Some say that individual stocks are more closely approximated by the lognormal distribution than a collection of stocks. For example, here's some samples, for comparison:

>The density distribution is rather erratic, eh?
Okay, here are the cumulative distributions:

However, I'd like to consider a distribution which approximates (for example) the S&P distribution:
 for part IV
for part IV
