| Principal Component Analysis |
Okay, here's the problem:
- We have a set of n variables, say R1, R2, ... Rn (such as the monthly returns for n stocks).
- The covariance matrix Θ is known (for these R-variables).
- Construct the linear combination: W = x1R1 + x2R2 + ... +xnRn.
- Choose the weights xk so as to maximize the Variance of the variable W.
>Huh?
Suppose the R-variables were the stock returns for umpteen stocks, say the stocks in the S&P500, and we wanted to construct a variable which
reflects the variations in that collection of stocks.
>Then just use the S&P500 Index, right?
Well, yes ... but many of those 500 stocks are so highly correlated that perhaps we could ignore some.
For example, suppose we took a single stock to represent the entire automobile industry and one to be a proxy for the computer industry and another to ...
>And end up with just 30 instead of 300? You're talkin' the DOW, eh?
Very good!
Let's write our column vectors like so: V = [v1, v2, ... ]
I know! It looks like a row vector ... but this notation don't take up so much room. 
Then here's the problem, in math-speak:
|
Given the n x n covariance matrix Θ, determine the n-vector of weights
X = [x1, x2, ... xn] such that
XT Θ X = maximum subject to the constraints: XT X = 1 and xk ≥ 0 for k = 1, 2, ...n. |
>That's the problem? What happened to the R-variables?
As it turns out, the Variance of a portfolio of n assets with covariance matrix Θ is given by:
σ2
= XT Θ X
= Θ11x12 + Θ22x22 + ... + Θnnx12
+ 2 Θ12 x1x2 + 2 Θ13 x1x2 + ... etc. etc.
SO, we maximize that Variance. However, we want our weights to be positive and the weight vector X to be of unit length ... hence the constraints.
>And can you solve that problem?
Here's what we know:
- The matrix Θ is symmetric.
- The eigenvalues λ and eigenvectors u satisfy Θ u = λ u.
- Symmetric matrices have real eigenvalues and, if they are all distinct, the eigenvectors are orthogonal.
That is: if uj and uk are two eigenvectors, ujTuk = 0. - If that is the case, and we write our X as a linear combination of the unit eigenvectors,
X = a1u1 + a2u2 + ...
+anun, then
XT Θ X = {a1u1T + a2u2T +...} Θ {a1u1 + a2u2 +...} = SUM of terms like: ajujT Θ akuk - But Θ uk = λkuk (since uk is an eigenvector) and ujTuk = 0 (since eigenvectors are orthogonal).
- Hence: XT Θ X = SUM of terms like: ajλjujTuj for j = 1, 2, ... n.
- Since we picked unit eigenvectors, then ujTuj = 1.
- Further, we required that XT X = 1, so that Σ aj2 = 1 for j = 1, 2, ... n.
|
XT Θ X
= Σ ajλj = maximum, for j = 1, 2, ... n
with Σ aj2 = 1. |
We're almost there!
Clearly we should identify the largest eigenvalue, say λ1, and choose a1 = 1 and all other aj = 0.
That'd make X = u1 and the weights that'd give the maximum variance are just the components of the
eigenvector associated with the largest eigenvalue.
Did you get that?
>zzzZZZ
Don't you see? If X = u1
(the eigenvector with the largest eigenvalue), then
Θ X = Θ u1 = λ1u1
and XT Θ X
= u1Tλ1u1 = λ1
... since u1Tu1 = 1
... and they ain't any bigger eigenvalue than λ1.
>And just how do you find that eigenvector associated with the largest eigenvalue?
Here's one way to identify the eigenvector of a matrix A associated with the largest eigenvalue:
- Pick any vector v.
- Multiply by your matrix A, giving Av.
- If v = a1u1 + a2u2 + ..., then Av = a1λ1u1 + a2λ2u2 + ...
- Repeating umpteen times, we get: ANv = a1λ1Nu1 + a2λ2Nu2 + ...
- After each preMultiplication by A, normalize the resultant vector so it's of unit length ... then continue multiplying by A.
- Eventually, the largest eigenvalue dominates and you're left with a1λ1Nu1, normalized to unit length- you've identified the appropriate eigenvalue u1.
>Huh?
Well, for example, suppose  and we start with, say v = [1.00, 0.25]
and we start with, say v = [1.00, 0.25]
We'll multiply by A, normalize, multiply again ... and again, and we'll see something like
this, where v is coloured blue
and Av is coloured red, then we normalize A v and it becomes our new v
so we colour it blue and the next multiplication (after nomalization) is coloured red again and ...
>Okay! I get it!
Did you see? After just five iterations the vector hardly changes. We've got ourselves the eigenvector u1.
>But what's that maximum Variance? I thought we ...
Haven't you been listening? The Variance is XT Θ X which is just
λ1, the largest eigenvalue ... when you choose X = u1.
>But have you reduced the number of components? I thought you were talking retaining the "principal: components and ...
Patience.
However, notice some things:
- The coVariance matrix Θ is real and symmetric and is (usually) obtained from historical data.
- If Θ is n x n, then we can expect n eigenvectors and n associated eigenvalues.
- The eigenvectors, satisfying Θ u = λ u, have a particular direction, but can be any length.
- If the n eigenvalues are λ1, λ2, ... λn, then the contribution to the variance provided by the eigenvector uk is λk / Σλj
- Although one can use the raw historical returns data to calculate Θ, it is better to "normalize" the returns by subtracting the Mean Return then dividing by the Standard Deviation.
>Huh?
If one of the assets has returns r1, r2, ... with Mean = m and Standard Deviation = m, then replace the set of returns
by (r1 - m)/s, (r2 - m)/s ...
That'll change the coVariance matrix into the Correlation matrix ... and that's good because we're only interested in the deviations of
returns from their mean, measured as multiples of their Standard Deviation.
>But have you reduced the number of components? I thought ...
If we're willing to accept the allocation identified by the eigenvector u1, then we've got a single number to represent the Variance
provided by the entire set of assets. In other words, if there were 500 stocks and we constructed a single Index composed of a particular allocation of
those 500 stocks (defined by u1), then we've got ourselves a
single number, right?
>That's confusing. Do you really understand this stuff?
Want the simple answer? No!
However, I have this spreadsheet that's fun to play with. It looks like this:
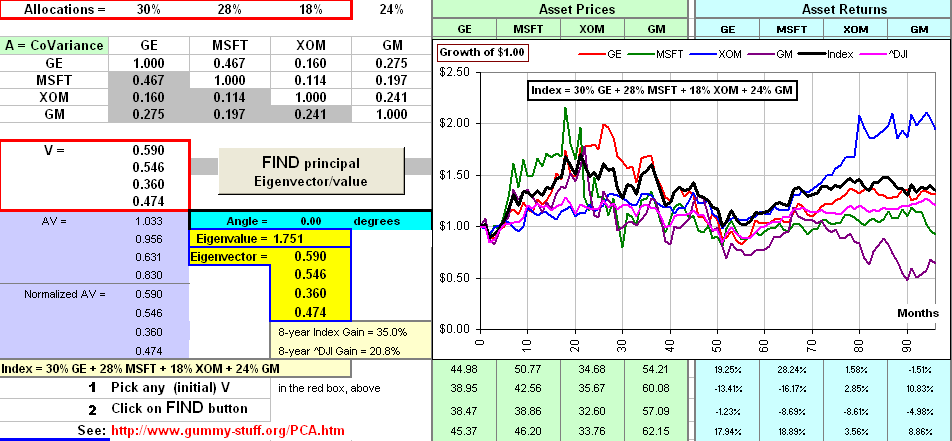 Click on picture to download spreadsheet
Click on picture to download spreadsheetIt'll download 8 years of historical monthly returns for four stocks and construct a coVariance matrix (called A in the spreadsheet).
There's a sheet called Assets which'll do that for you. You can also download (and plot) a "comparison" stock ... like ^DJI.
You then type in some initial 4-vector to start (called V in the spreadsheet) and click a button.
The largest eigenvalue and associated eigenvector are then identified.
>So, in the example, the allocation 30% GE + 28% MSFT + 18% XOM + 24% GM ... does what?
Supposedly, that combination will explain "most" of the Variance of those four stocks ... in a single number.
>And does it?
How would I know? 
Anyway, if you're not satsified that the "principal" eigenvector doesn't reflect the collection of stocks, add the next eigenvector,
associated with the next largest eigenvalue ... and so on and so on.
>And where are all the other eigenvectors and eigenvalues?
I haven't found them ... yet!
Notes:
The spreadsheet does a bunch of A-multiplications of your initial V, normalizing after each multiplication, until the angle between V and AV is (effectively) 0 degrees. That means that AV and V are in the same direction, so one is a scalar multiple of the other. That is, AV = λV and we've got our eigenvalue/vector pair.Also, the "Normalized" returns are used for each stock, so the coVariance matrix is really the Correlation matrix.
Having found the "principal" eigenvector and eigenvalue, we'd see if the contribution to our "Index" is large enough.
If not, we look at the next largest eigenvalue and associated eigenvector.
>The next largest? How do you find that?
Since the eigenvectors / eigenvalues satisfy AV = λV, then (A - λI) V = 0, so the matrix
A - λI must have a zero determinant.
So, putting det |A - λI | = 0, that gives a polynomial equation to solve for the various eigenvalues λk.
The spreadsheet has a plot of this polynomial, somewhere (which, in our case happens to be of 4th order) and ...
|
>Picture, please!
It looks like this Notice the size of the largest of the four eigenvalues? >I'd say it was ... uh, 1.7 or thereabouts.
So the "weights" associated with the four stocks are:
| 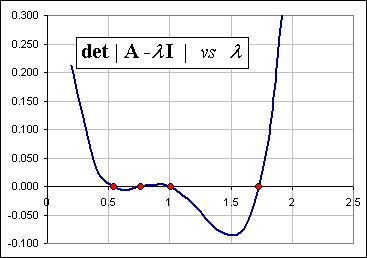 |
You stare at the chart, select four Guesses, then click a button to get better and better estimates.
The spreadsheet will do that, somewhere ... like this.
>Is that 13%+19%+25%+43% good ... or what?
How would I know?
>What do you know?
How would I know?
|
>Well, at least let's see another example!
Okay, here's 8 years worth of four monthly mutual fund returns: VFINX (a 500 Index) VBMFX (Total Bond Index) VIVAX (a Value Fund) VGTSX (International Fund) The eigenvalues, 0.069, 0.235, 0.933 and 2.763, are here >Hey! That largest eigenvalue is really big compared to the others, eh?
| 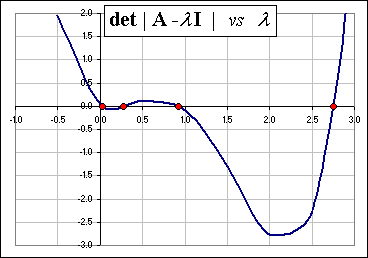 |
Actually, it isn't. It's always the trace of the coVariance matrix = sum of the diagonal elements (which have the value "1") ... so for "4" stocks it'd be "4".
>And the principal eigenvector?
The principal eigenvector is [0.580, -0.191, 0.571, 0.549] which means the allocations should be in these proportions,
and that gives (to the nearest integer):
38%, -13%, 38% and 37% (adding to 100%) and ...
>Wait a minute! A negative percentage? Are you kidding?
Uh ... well, I understand that sometimes happens so ...
>Sometimes happens! Are you kidding?
The math doesn't know, yet, that the weights have to be positive, so ...
>Then tell it!
Patience.
In the meantime, consider allocating a 4-stock portfolio according to the weights assigned by that principal eigenvector.
|
For example, considering the 30 stocks on the DOW, Ron McEwan identified four as being top ranked, according to PCA:
MMM, MO, JNJ and CAT. The principal eigenvector (normalized to a unit vector) turned out to be:
A Portfolio of 33% MMM + 17% MO + 19% JNJ + 31% CAT had a chart like so See the Portfolio ... and see the DOW itself?
>So your portfolio was up 200%?
| 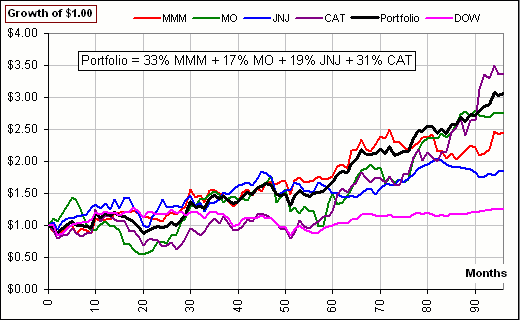 |
 for Part II
for Part II
The pictures and spreadsheet may change without noitce

){kind=link}
){kind=link}
){kind=link}